
Causal disentanglement
Picturing causal relationships between genes, environments and outcomes.

If you are reading this, there is a fair chance that you are nearsighted. Nearsightedness is a very common affliction in Western and East Asian countries, less so in other regions. It is an interesting puzzle, because it has an obvious genetic and racial component despite the fact that it would have been a big problem for most people living in a premodern environment. It is also rapidly becoming more common, suggesting a decisive environmental factor despite the absence of any obvious candidate. The increase began in the 1950s in the West, and in the 1980s in East Asia. It was known to be common among scholars before that, and it is reliably associated with intellectual achievement (which is mostly genetic). It started later than the advent of mass literacy in Europe. It predates the advent of modern electronic devices, and it is too sudden to be caused by the slower-moving process of urbanization. Maybe the television played a role, although if that were the case, it would have been very easy to test: many families in the 1960s still did not have a television.
Myopia is a complex topic, but this post is not about myopia – it is about the complexity. Which mental framework or model should we use when inquiring about individual outcomes?
A good mental framework can help us grasp complex questions easily. I believe the model most people have in mind when trying to disentangle nature from nurture is something like this:

The arrows represent causal relationships. So, if that graph applies to an individual, each one of the factors on the left accounts for a fraction of the outcome, and together they account for all of it. It it applies to a population, each of the variables on the left accounts for part of the total variance in outcomes, and the sum of all “variances explained” is 1.
This model raises more questions than it answers. Let’s improve upon it step by step, by going through various examples. Only well-known examples will be used, to see how they fit into the model. Towards the end, we will simplify it again.
Genes have a direct impact on the chances of dying from homicide, because genes influence (among other things) personality traits and ability for long-term thinking. A more violent and impulsive individual is much more likely to get into a fight. But genes also have an indirect impact: they strongly determine social status. Even if the individual is not particularly violent, genes have an indirect influence on the kind of social environment someone is likely to interact with.
For someone to be in that specific environment at that fateful moment is also not fully determined by a prior state of affairs and genes. It is also somewhat random. So, we need to add a couple of arrows to our model: genes influence the environment, and the environment is partially random.

Let us see if we can use this to model someone’s risk of falling sick with malaria in the fifteenth century. The outcome is having malaria. It has genetic factors (the presence or not of the allele responsible for sickle cell disease), environmental factors (being in an affected region at the time of an epidemic) and it is partially down to chance. The environment in question, however, is not meaningfully affected by genes, since almost no one would have migrated in the north-south direction at the time.
Is the environment the person finds themselves in fully random? Well, no, in all likelihood it is the environment where their parents and a lot of their ancestors lived. So, we might add another cause to the environment: the past environment.
There is a problem with that: some of the past environment was the ancestral environment, and that had an influence on genes through selection. So, we need to refine the model again.
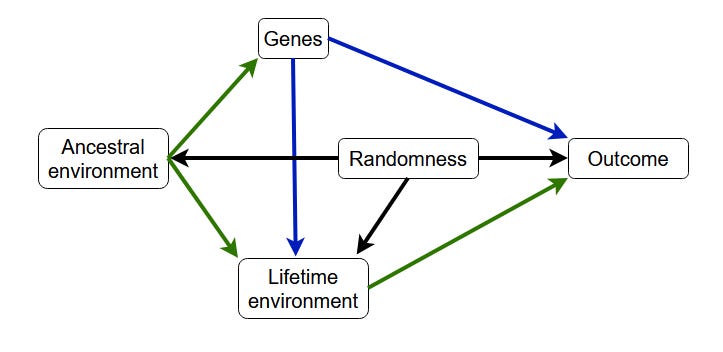
Some islands in the Pacific have obesity rates in excess of 70%. This is caused, as all things are, by the interaction between their genes and their lifetime environment. Their lifetime environment is (for the most part) the same island biome their ancestors used to live in, a social environment that is partly the expression of their genes, and… the introduction of a type of diet that was not a part of their ancestral environment. So, we should add a “Non-ancestral environment” rectangle.
This is a distinction worth making, because the ancestral and non-ancestral environment are neatly delineated complements: every outcome ultimately comes from these two causal sources, bar some random noise.
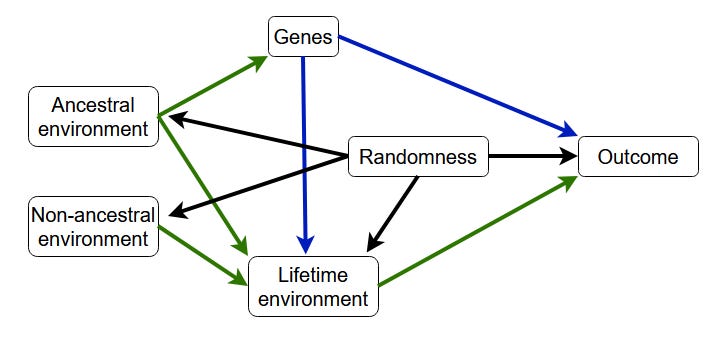
The increase in abstract reasoning ability that followed the invention of agriculture (documented in The 10,000-year explosion by Cochran and Harpending) was brought about by a positive feedback loop: a more demanding settled lifestyle causes an increase in intelligence, and that increase in turn causes society to become more complex and impose stricter rules. So, genes are not only causal towards the lifetime environment, they were causal towards the ancestral environment as well.

Lastly, what is the difference between homozygotes and heterozygotes? Obviously, homozygotes share the same gene variants, which is why they are a fruitful natural experiment: they provide a control for genetic effects.
However, this exposes a problem with the causal model above: heterozygotes have the same ancestral environment, and yet they do not have the same genes. So, we should add another arrow, to account for the fact that sexual reproduction randomizes the inheritance process. After that, the model seems complete.

This is a lot messier than the original, but it better reflects reality. This model readily maps onto almost all questions of genetic inference, and helps us understand what is being described. In a coming post, I will describe how it applies to various outcomes: the spread of fashions among the schizophrenic, the lack of influence of parenting style on adult achievement, and the modern pattern of low fertility.
As I said earlier, it accounts for all of the causes of the studied outcome, in an absolute sense. However, we can simplify it, because in practice we are never studying outcomes directly: we are studying how much of the variation in an independent variable explains the variation in a dependent variable (the outcome). In a large sample, we can ignore the contribution of randomness, because the noise cancels out. This gives us the final result:

To be clear, randomness can influence the population as a whole as well as an individual. We can only ignore it when we are considering an “averaged out individual” within the population.
Graphs made using draw.io
I'm glad that you're bringing attention to this, because I don't think this topic gets enough emphasis in statistics and other fields.
This Wikipedia article is probably relevant: https://en.wikipedia.org/wiki/Causal_graph